Immersa offers a data automation platform that connects product usage data to sales, service, and marketing in order to increase SaaS revenue.
The right data in the right context empowers individuals, delights customers, and helps accelerate businesses. Immersa automatically connects to any data source and brings together only the customer data you need. It also combines Product and Customer Data From Any Source.
Immersa can find revenue signals in product/customer data for your sales and service teams by analyzing customer behavior. Immersa sends actionable, qualified product leads directly to your sales reps and customer success agents in your CRM of choice
Our Responsibilities
Since Immersa offers a data automation platform, they need scalable and robust services that sync customer data from different CRMs like Salesforce, Intercom, Hubspot, and many more. These services are called Connectors and we have developed many connectors for them.
The two basic features of the connector are ETL and ReverseETL. ETL features support customer data in Historical and Incremental Sync. Historical sync basically sync complete customer data from your given CRMs to Snowflake or any Desired location. Increments sync, sync customer data in regular basis from a given point of time. Increments sync is also flexible enough to sync real time customer data.
Scalable Connector Architecture
We have developed a connector service based on the pluggable architecture, which means just plug any CRM native module into the service and you are ready to sync.
The connector architecture falls into three components. Service, Plugin Core Type, and CRM native plugin. Service is the main core part where the CRM native plugin gets installed, and their native plugin is generated by implementing the Plugin Core Type.
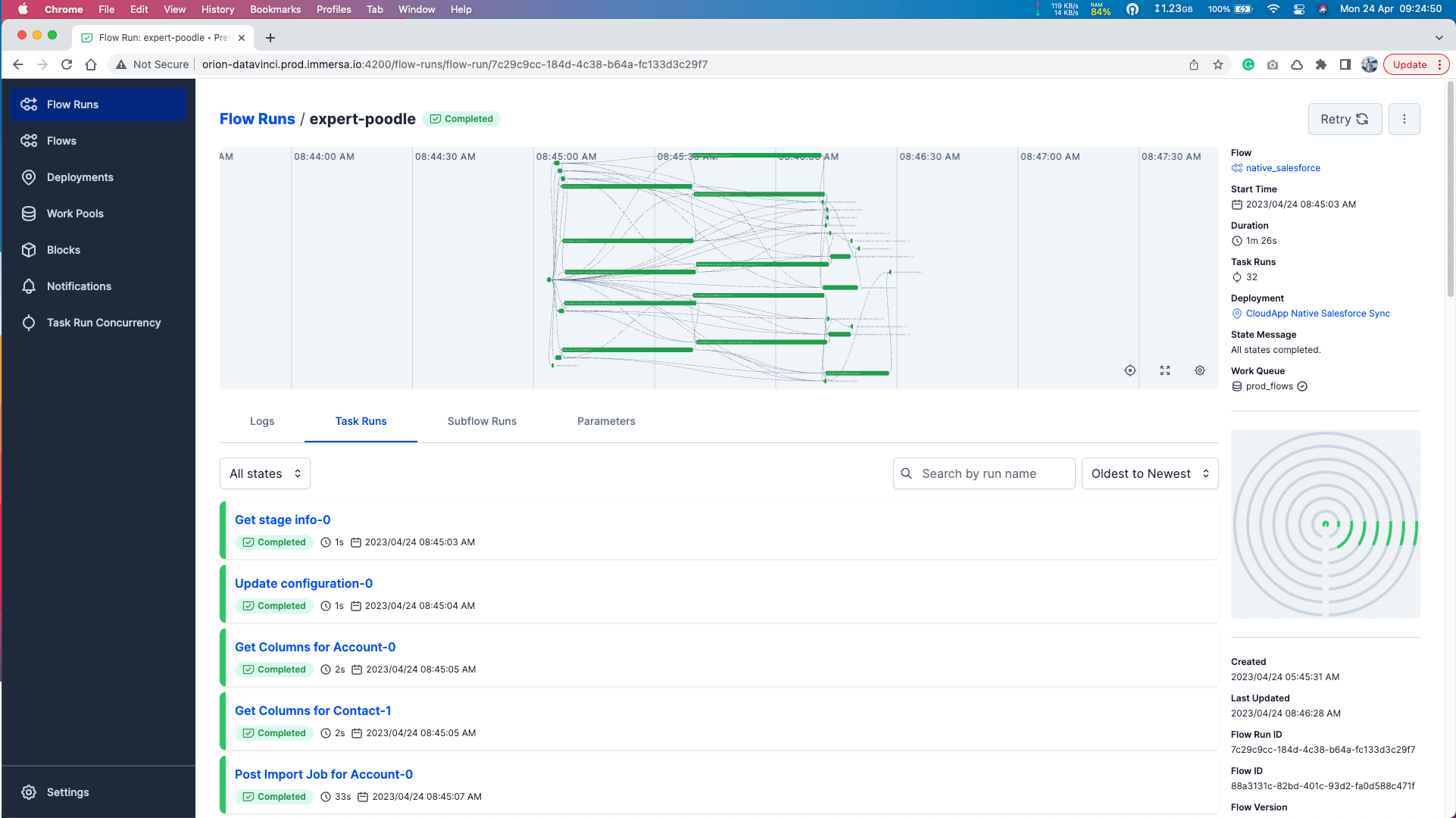
Let’s go through a case where we have to fetch data from Salesforce and load the data to Snowflake. In this process the orchestration flow will call the connector service endpoint, this service will add a job into the queue and store the job information in the DB. Once the queue consumer will get called this will call the native CRM plugin, this plugin will interact with CRM through their endpoints and return the customer data response to the service. The service will stream the data and create a csv file on the AWS S3 bucket. Finally, flow will read the file and load data to the Snowflake database.
Orchestration
Orchestration is the process of integrating two or more applications and/or services together to automate a process or synchronize data in real time.
So, the services provided by the connector are integrated together in such a way that syncs customer data from given CRMs to Snowflake or any desired location. This integration is called flow, which contains a certain none of the task to achieve the goals.
To meet our requirements we have used an orchestration tool/ framework called Prefect written in Python. Perfect allows configuring, scheduling, and UI to monitor the sync process.
Connector Service
This is the main core part of the connector written in NestJS(A progressive Node.js framework). Where we implement Service APIs, Queue, Jobs, Database services, and loading customer data to the AWS S3 bucket. Connector exposes various REST services where orchestration flow interacts with the service. Like saving/updating the configurations, adding a job, retrieving the job status, etc.
Storing all jobs using MongoDB
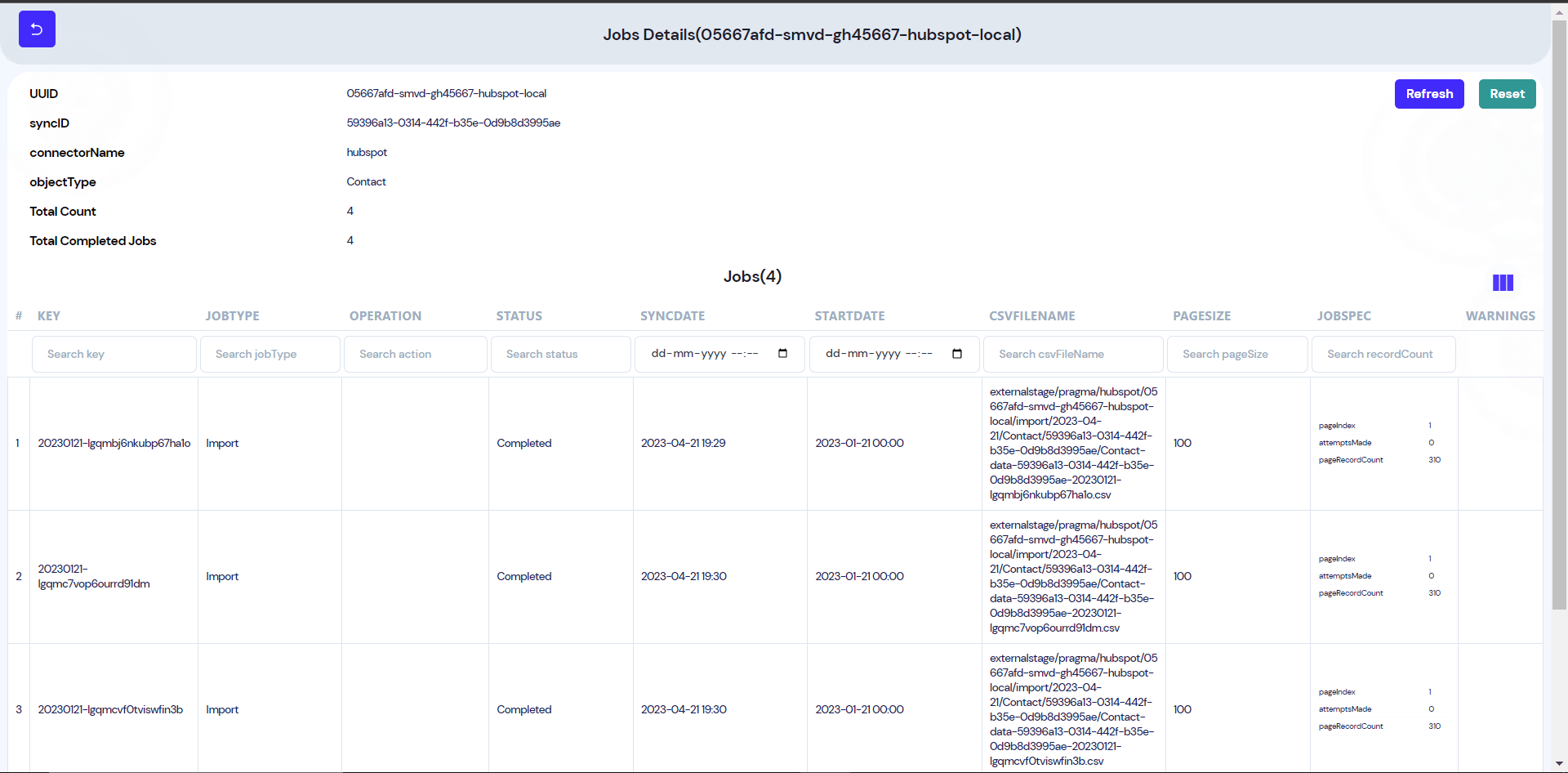
This is the data structure maintained by the service. Since connector service supports different types of entities for CRMs, we need a data structure to store such information. The job contains the information related to the sync process like what object needs to be synced? Is it ETL or reverse ETL? What are the data source CRMs and metadata related to the object? This job is shared with the native CRM plugins. To store the jobs MongoDB is used, that suits our requirements. We also capture the error as well so in near future we can automate the process to resync the failed jobs.
Maintained operations in Queue for scalability and load balancing
Since it’s hard to call and maintain the connection the CRMs API is in a loop to retrieve/export bulk customer data to or from CRMs. That’s why we thought of implementing a queue. The benefit of using a queue is to retry the failed jobs, capture the current state of jobs, reduce the API rate limit, etc. We have used BullMQ, a Node.js library that implements a fast and robust queue system built on top of Redis that helps in resolving many modern-age microservices architectures.
Pluggable Architecture
We have built the connectors using a pluggable architecture where the connector service can be plugged in with various connectors for each CRM /Data Source. The plugin directly interacts with the CRMs endpoint, to authenticate, retrieve, and update the records. This native plugin is installed/plugged to the connector service. The plugin is developed by inheriting the abstract classes/method as defined in the core type.
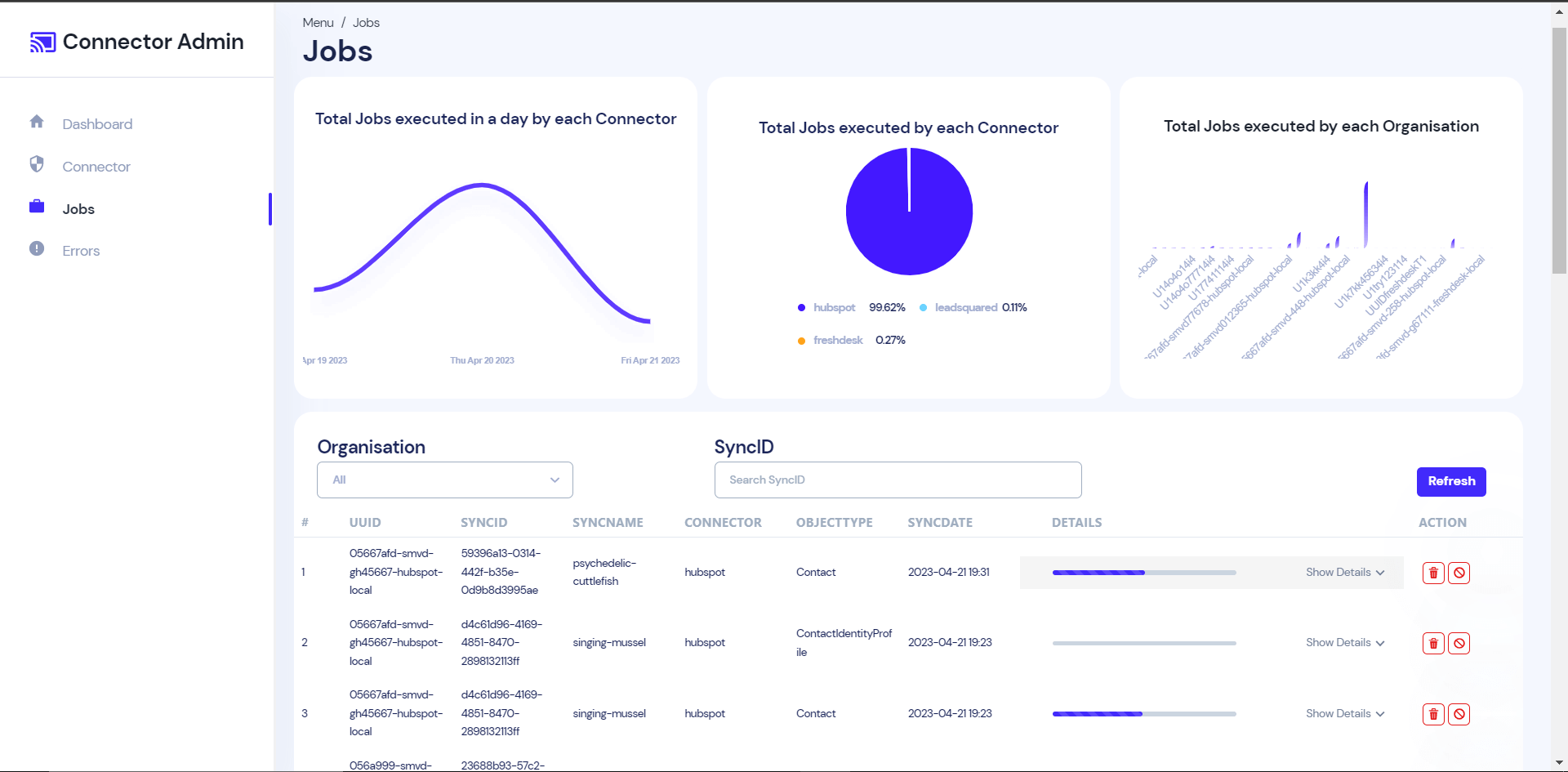
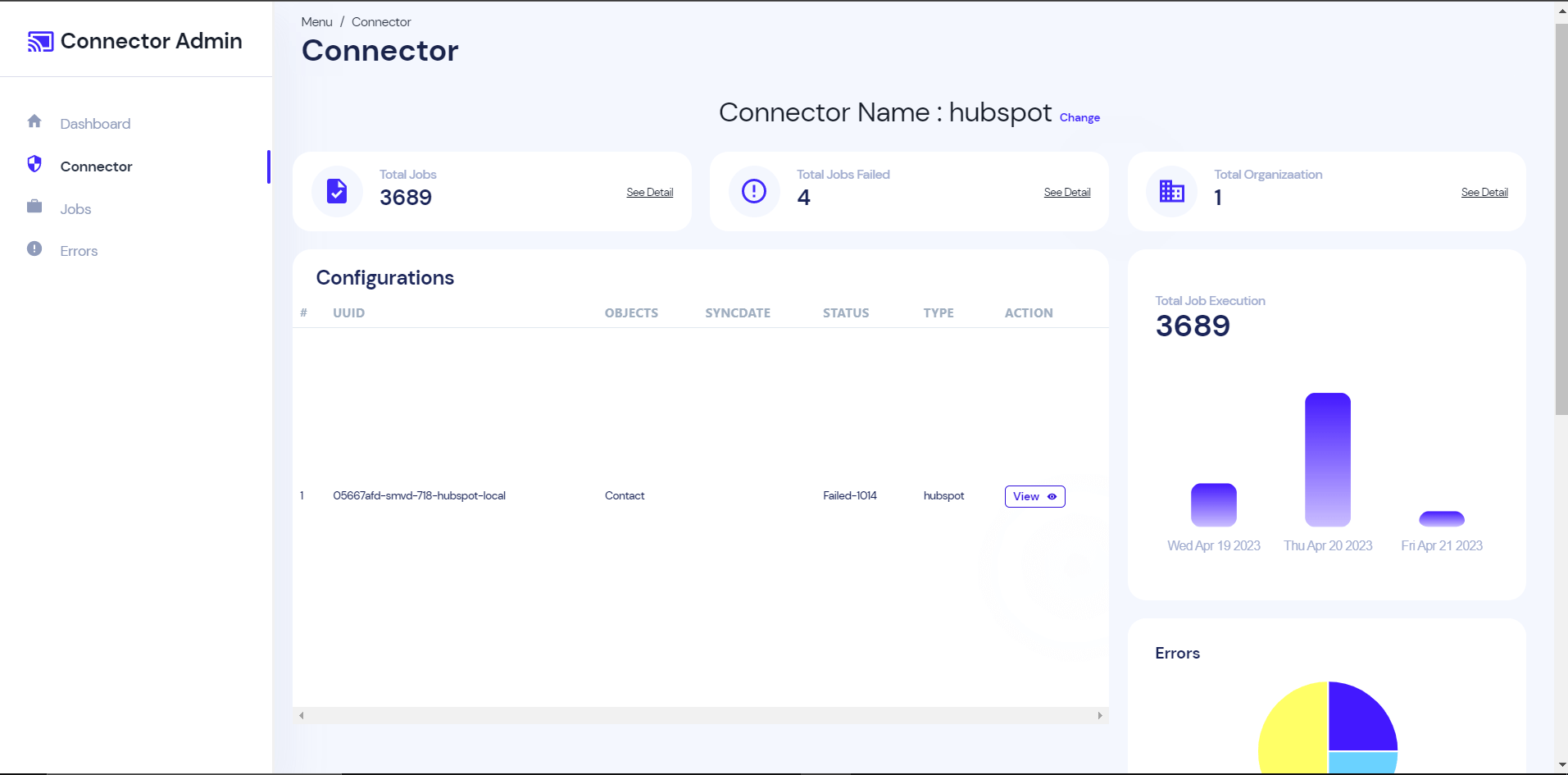
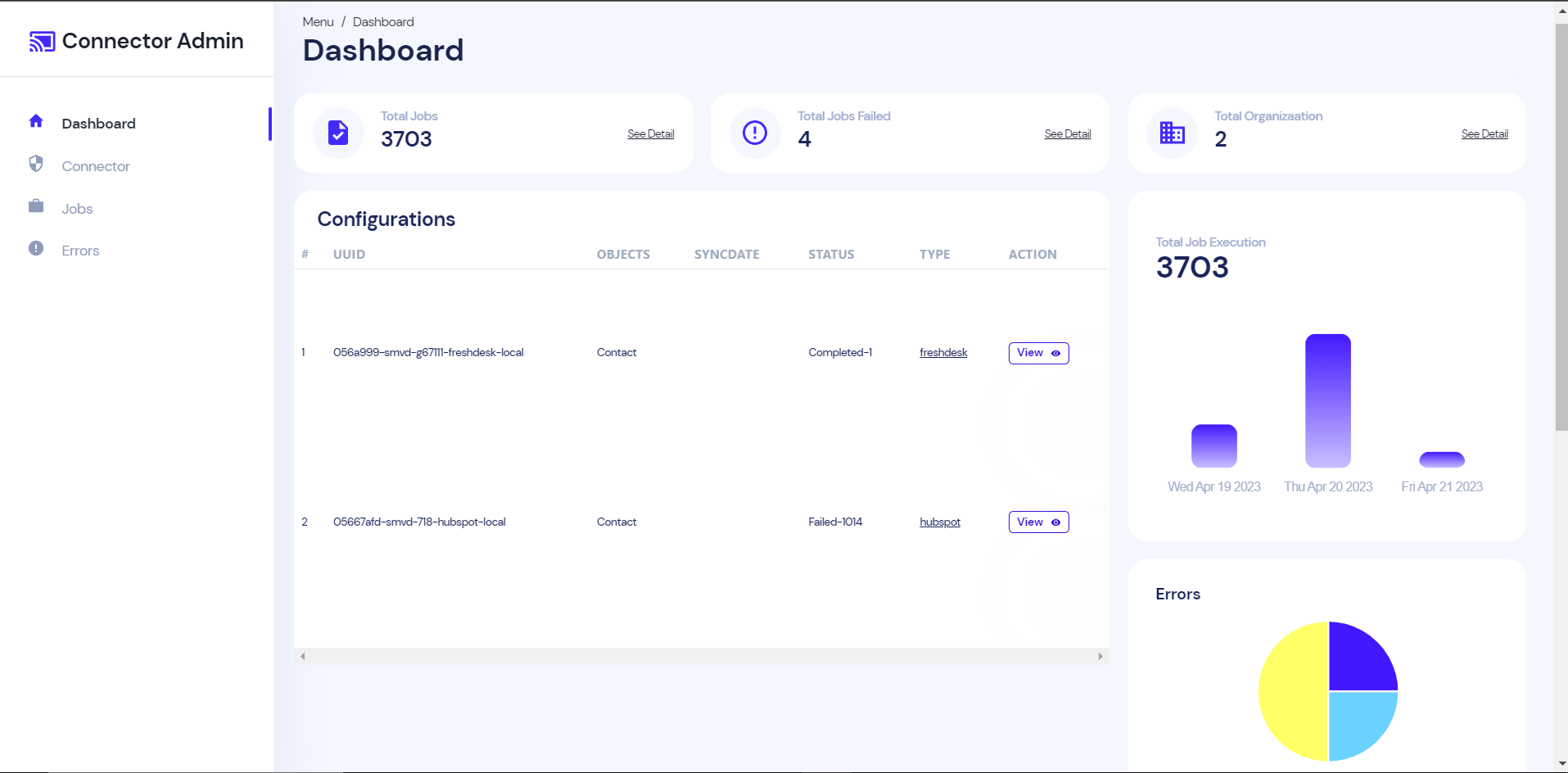
Connector Admin
We are also working on a React web app where Immersa can view the detailed information of their client. We have exposed a few REST services in the connector service, this app will consume those REST API and display graphical and meaningful information about the customer data sync. For example How many clients sync the information? The type and no of connectors used by a client? What is the current sync status? Is there any sync failure etc?
This is not in production yet, but will live soon in the near future.
Loading the Data to the snowflake
Connector services stream the customer data available in JSON format to AWS S3 bucket and generate csv files. The CSV files are directly mapped with a job. So, multiple files are created for a single sync and single objects.
The orchestration flow task reads the files from the S3 bucket and loads these data into the snowflake database. While loading the customer data it updates the existing records and inserts new records.
Connectors We Developed
Salesforce
This is one of the giant CRM and it has billions of records for an organization. So this huge challenge to sync(ETL) these records even if we can’t miss a single record. How much time is taken for sync?
Sync millions of records
There are millions of records for different types of standards objects like Accounts, Contacts, Users, Lead, Case, Opportunity. We also sync the customer custom objects. We also provide support for historical objects like Contact History etc.
Added sync support for both way Historical and incremental sync. Also handled the compound fields(Compound fields group together multiple elements of primitive data types, such as numbers or strings, to represent complex data types, such as a location or an address) as well.
Integration of Bulk APIs
We have integrated Salesforce bulk API. We post a job with the desired query in the Salesforce, wait till the job completion then we fetch the job result from salesforce in a page. Due to the limitation in the response page size, we have to iterate the process for various numbers of time. To overcome this situation we have used the queue mechanism. Initially we add a job to the queue to get the very first page. Once the job is added the job consumer then processes the job to get the page. Based on the response we add a new job to fetch further records.
Special Handling of Custom Fields
We fetch the records and load data to Snowflake. Snowflake may have few more or less columns as compared to the Salesforce objects fields and vise versa. So we have added a special handling for such types of fields. As per our current implementation in such a case we only show warnings. In the near future we will automate this process and create columns/fields accordingly.
Intercom
Intercom is a Customer Service Solution. According to the client requirement we have to develop a connector for Intercom as well.
Sync millions of records
Similar to Salesforce we have to sync millions of records. Intercom also has different types of objects like Contacts, Company, Team, Admin, Conversations etc. The most complex is the Conversations. Also we have to support Historical and Incremental sync as well.
Integration of APIs
Unlike the Salesforce it doesn’t have a job mechanism. We have to call the Intercom API directly to get the desired records. Due to API rate limit we also need to take care of HTTP requests made per second. The most complex part is synchronization of the Conversation object. For each conversation we have to call a Conversation object detail REST API. So if there are thousands of conversations then we have to make thousands of calls to get the details of that conversation. So without the queue it’s almost impossible.
Special Handling of HTTP request to reduce the sync time
Most of the clients have their 5-10 years records. To fetch millions of records we have to make thousands of http requests to get all the records in a row. If we make those requests in a row then it will take days to fetch the records. So we have to make the requests in parallel. We have introduced an interval. So if the interval is 30 then for a year there will be 12-13 jobs with the interval of 30 days. And each job will fetch their respective records and will create the next page for their own date range.
Hubspot
Sync millions of records
Similar to Salesforce we have to sync millions of records. Hubspot also has different types of objects like Contacts, Company, Deals, etc. The most complex is the Deal. Also we have to support Historical and Incremental sync as well.
Integration of APIs
The API integration is quite similar to the Intercom for the ETL. But we have also implemented Reverse ETL, which means we are adding a bulk of records from Snowflake to the HubSpot account. Taking care of all the limitations like no of records can we add to a single batch, deleting and modifying the existing records etc.
LeadSquared
Sync millions of records
Similar to Salesforce we have to sync millions of records. Leasquared also has different types of objects like Lead, Contact, users, Deals, etc. The most complex is the Activity. Also we have to support Historical and Incremental sync as well.
Technology Used
- Application Programming: Javascript, Python
- Frameworks/Libraries: NestJS, Prefect v2, ReactJS
- Queue: Redis
- Database: MongoDB, Snowflake
- Cloud Services: AWS S3, EKS (Kubernetes), DuploCloud